














Here I explore the benefits of utilizing SIEM solutions and outline some very important performance and resource considerations that need to be evaluated and provided for, as well as how to resolve these challenges.
What is SIEM?
Security Information and Event Management, or SIEM, is essentially a hybrid of log management and security analytics that allows your organisation to proactively detect and respond to possible threats in your infrastructure.
Popular enterprise SIEM solutions include:
The detection side of a SIEM solution is somewhat like a Web Application Firewall (WAF) rule set and engine that is constantly applied to your infrastructure's logs and events by an automatic service, often in near real-time.
A SIEM solution will also usually provide an analytics tool or dashboard for visualizing the results, generating reports, and a back-end for collecting and storing the event data. Some of the more advanced solutions include technologies such as User and Entity Behavior Analytics (UEBA) and Machine Learning (ML), which are intended to dynamically detect possible security events using profiling and pattern analysis.
By far the most useful functionality is being able to see security-related patterns across organization-wide system events and to automatically detect common security risks, as well as catching outlier endpoints within an infrastructure that might have security compliance issues.
Many SIEMs also provide an endpoint monitoring agent for installation on workstations and servers that provide direct reporting back to the solution, which greatly enhances their usefulness for organization-wide security management.
Why should I use SIEM?
The obvious prerequisite for any robust security strategy is effective auditing. I recall the trouble we had with network security auditing in the early part of my career in network administration and systems development back in the early 2000s...which seems like ancient history now.
Back then, most security threat analysis from event and log data collection tended to happen after the fact, and we used to do it rather laboriously using manual, piecemeal techniques that all needed to be documented and reviewed by hand.
For a medium or large-sized organisation, it tied up key personnel with specific systems competencies for extended periods of time, which was a most unpalatable prospect from a resource management perspective.
As a result, a detailed system-wide security audit was often seen by management as a universally disliked activity to be performed during a quiet month (which, of course, never happened). The mere suggestion of another security audit would result in audible howls of displeasure from my colleagues due to the huge amount of time, effort and stress involved in completing the exercise.
Almost all enterprises could do with investing in SIEM to implement real-time, automatic, and fully holistic security analysis.
Mostly, we were assigned to do security auditing only if we suspected an intrusion or data breach, or to check if a known vulnerability had been successfully mitigated. Naturally, this chaotic approach often resulted in a lot of firefighting and lost nights of sleep.
By reacting only if and when an event of sufficient visibility occurred that clearly indicated an actual or potential problem, we were often too late. This is precisely the set of problems that a SIEM solution can help with — by converting security audits into a continuous improvement activity driven by automated data collection, alerting, and intelligent analysis. I would go so far as to say that almost all enterprises could do with investing in SIEM to allow implementation of real-time, automatic, and fully holistic security analysis.
In today's much faster-paced security landscape, I'd say that it's becoming humanly impossible to manually keep up with the possible range and breadth of security risks in an organisation using an unstructured and decentralized approach that relies entirely on IT team resourcing.
Achieving all-systems coverage in SIEM permits much better event correlation across your business, faster threat detection, and more thorough compliance auditing. Such an approach facilitates centralised automation and reporting to make better and more effective use of personnel time and attention, considerably reducing (although of course, not eliminating) the human labor required to implement proactive security.
The problem: SIEM and resource scaling
However, for this to work correctly in anything larger than a small organization with an equally small topology, this involves a very large amount of traffic passing through the SIEM solution, which only grows over time and must be correctly managed. If SIEM is the "organizational octopus," if you will, of security data collection, the most effective implementations will have a tentacle in most (if not all) corners of your IT infrastructure. As a result, there are some very important performance and resource considerations that need to be evaluated and provided for, preferably before they become an issue.
Many are related to the resources required in order to handle the enormous amount of event data being ingested into (and collected by) the SIEM solution. As traffic within a network infrastructure scales up over time with increased utilization of services and nodes, the corresponding SIEM event volume to be ingested increases and scales up with it (in some cases exponentially), requiring ever-greater network and database resources in order to support it.
In particular, having just a single SIEM collector node in the deployment quickly becomes problematic, as many of our customers have found. Not only does it create a single point of failure for the SIEM solution as a whole, thus defeating the concept of high availability (HA) and risking loss of critical event data in the event of that one node failing, but it also creates a single network-wide bottleneck that can negatively impact on application performance where the SIEM is used as a destination for remote system logs.
The next logical step is to add additional collectors to the cluster and manually divide the SIEM event sources between them with 1:1 mapping, which does initially improve the situation somewhat in that it allocates more resources to each source. However, doing this still has not addressed the HA situation, because if that event source's assigned collector is down for whatever reason, the event data is still lost. Additionally, resource utilization remains unevenly distributed between the collectors because capacity cannot be shared across all of the incoming throughput of events.
The solution: load balancing with an ADC
A load balancer (also known as an application delivery controller, or ADC) shares network traffic across a group of servers that belong to a particular virtual service, and monitors the status of them to determine whether they are able to receive incoming requests. These come in various shapes and sizes, including our own product, the Loadbalancer.org Enterprise ADC. Depending on their feature set, they can also intelligently control how much traffic is sent to each, based on metrics such as current system load.
Example: Splunk
Here's an example of how to load balance the SIEM application Splunk:
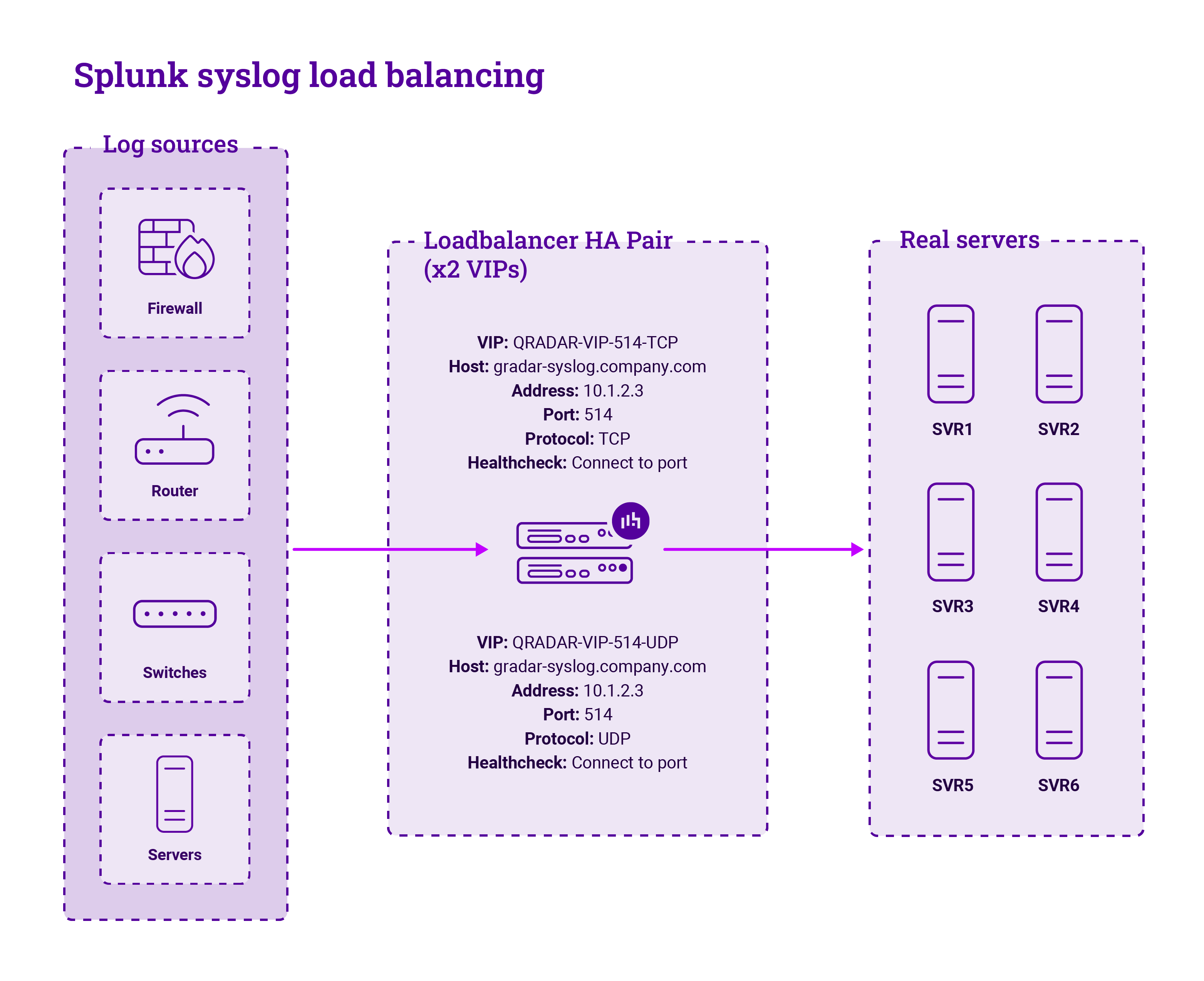
In the case of a SIEM solution, the approach is to load balance the ingestion of SIEM data into the collectors, spreading the event traffic evenly across the cluster members. Such an approach means that all of the various event sources can share the available resources of the ingestion side of the SIEM, resulting in better performance and utilization of available network resources.
Furthermore, with a load balancer between the SIEM event sources and the collection nodes, failure of a single node will not usually result in an interruption in SIEM data collection, provided sufficient resources are still available across the other cluster members. This permits individual cluster members to be taken offline for maintenance.
This configuration is achieved by defining a Virtual IP (VIP) service on a load balancer that represents the entire cluster of SIEM ingestion services for the solution, and the load balancer will then share the traffic load across those available ingestion servers as the data comes in. For mixed-mode UDP/TCP mixed-mode traffic such as remote system logs, creating this as a Layer 4 service within the Loadbalancer appliance will allow both protocols to be passed to the Real Servers.
In conclusion
SIEM solutions are increasingly a "must-have" within organizational network infrastructures, as both the scope and scale of network events and logging data have now reached the point where manual analysis cannot keep up with the volume being generated. Novel threats can emerge too quickly for manual intervention to be an effective prevention strategy.
In addition, analyzing logs and events after the fact is too slow to detect a developing threat within an organizational network. SIEM solutions are a powerful tool in implementing a proactive, continuous approach to security auditing as a far superior alternative to periodic methods.
Much of the utility of SIEM relies on obtaining large quantities of real-time event data from an organisation's infrastructure. This can result in major scaling issues in relation to the amount of incoming data through the ingestion process.
However, with load balancing on the ingestion side of the SIEM solution, this issue can easily be mitigated, along with improving the availability and performance of the SIEM service.