
Multi-site Active-Active Splunk SmartStore with NetApp StorageGRID and Global Server Load Balancing (GSLB)
Storage Published on •5 mins Last updated
Here we look at a Splunk SmartStore architecture that utilizes NetApp StorageGRID and Global Server Load Balancing (GSLB) to provide resilience and high availability.
The current explosion in the amount of machine-generated data is one of the fastest growing and most complex areas of big data. Containing concise details of machine behaviour, user transactions, customer behavior, security related anomalies, fraudulent activity and much more, it has become critical that this data can be accessed and queried whenever/wherever required. Splunk Enterprise enables this data to be ingested and converted into valuable insights, no matter what business you're in.
About Splunk Enterprise
Splunk Enterprise enables you to search, analyze, and visualize the data gathered from the components of your IT infrastructure or business. Splunk Enterprise is able to ingest virtually any type of time series machine data including logs from websites and applications, network device logs, Microsoft server event logs, streaming data from sensors and devices, message files, archive files and so on. After you define the data source, Splunk Enterprise indexes the data stream and parses it into a series of individual events that you can view and search. Most users connect to Splunk Enterprise with a web browser and use Splunk Web to administer their deployment, manage and create knowledge objects, run searches, create pivots and reports etc.
Splunk Classic Architecture
In the original classic architecture, indexers store data across the whole data lifecycle on a server accessible file system. This can be a direct-attached storage (DAS) filesystem only, or a combination of DAS storage and NAS or SAN storage.
Classic Architecture:
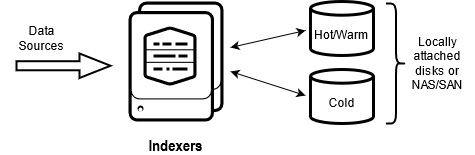
Splunk SmartStore Architecture
With SmartStore, storage has been decoupled from compute on the indexing tier and enables a more flexible indexing tier deployment. This allows compute and storage resources to be scaled individually depending on specific requirements. Warm data is stored in cost optimized S3 object storage which helps reduce deployment costs.
SmartStore Architecture:
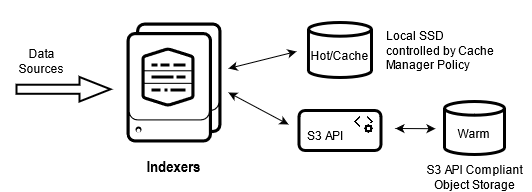
Each indexer incorporates a Cache Manager that manages the SmartStore data in local storage. The Cache Manager attempts to maintain in local storage any data that is likely to participate in future searches. By caching the search working set, the Cache Manager minimizes the potential of search delays resulting from data being downloaded from the remote store. Each indexer's Cache Manager operates independently from those on other indexers. The Cache Manager copies buckets from local to remote storage when the buckets roll from hot to warm, fetches bucket files from remote storage into the local storage cache when a search needs the files and evicts files from the local storage cache when they are no longer likely to be needed for future searches.
About NetApp StorageGRID
NetApp StorageGRID is a high-performance and cost-effective S3 API compliant object storage platform that is an ideal candidate for use with Splunk SmartStore. It offers intelligent, policy-driven global data management using a distributed, node-based grid architecture. It simplifies the management of petabytes of unstructured data and billions of objects through its ubiquitous global object namespace combined with sophisticated data management features. Single-call object access extends across sites and simplifies high availability architectures while ensuring continual object access regardless of site or infrastructure outages. StorageGRID can be deployed as optimized hardware appliances, virtual machines, Docker containers or a combination of all three.
Local StorageGRID node load balancing is normally handled by the built in storageGRID load balancing capability. It can also be handled by the Loadbalancer.org appliance if preferred. Both scenarios are detailed in our NetApp StorageGRID deployment guide. For deployments that are distributed across multiple sites, GSLB must be used.
Additional information on deploying NetApp StorageGRID with Splunk SmartStore can be found in the NetApp technical report "NetApp StorageGRID with Splunk SmartStore".
Global Server Load Balancing (GSLB)
GSLB enables the load balancers to provide intelligent DNS responses to inbound client queries for the Splunk SmartStore sub-domain (s3.company.com). The responses given depend on the health of the StorageGRID nodes in each site as well as the source of the request. This is achieved through DNS delegation where responsibility for the SmartStore subdomain is handed over to the GSLB service on the load balancers. It’s worth mentioning at this point that GSLB is included by default on all Loadbalancer.org appliances at no extra cost.
Deployment Architecture

As mentioned here, an on-premises Enterprise Splunk SmartStore deployment is limited to two sites. Both sites host active replicated object stores. One site hosts an active Cluster Manager Node and the other site hosts a standby Cluster Manager Node. This architecture enables continued operation in the event of an object storage failure at one of the sites as well as failure of an entire site. In the case of an object store failure, GSLB will redirect traffic to the remaining site. Due to replication lag, this site might be missing data recently uploaded to the failed object store. This will be rectified when the failed object store returns to service. For failure of an entire site, some manual intervention is required to switch to the standby Cluster Manager node. Some in-progress searches might return incomplete results if the search heads were accessing peers on the failed site. New searches are automatically redirected to peers on the remaining site. Any remaining operational forwarders at the failed site that are configured for load balancing across the cluster will automatically redirect to peers on the remaining site via the built in Splunk AutoLB functionality.
Making the most of your Loadbalancer.org Investment
Whilst Splunk automatically handles load balancing between forwarders and indexers via AutoLB, Splunk state that a 3rd party load balancer must be deployed to handle the following additional load balancing requirements:
- Load balancing inbound search requests across multiple Splunk Search Heads
- Load balancing inbound data between multiple HTTP Event Collectors (HECs)
- Load balancing traffic from the Syslog Collector (SC4S) to the Indexers
Virtual Services (VIPs) for all 3 requirements can easily be configured on the same load balancers deployed to handle GSLB.
For additional search resilience, the Virtual Service (VIP) configured to load balance the Search Head Cluster in each site can be configured to use the search head cluster in the opposite site as a fallback in case a Search Head Cluster fails. It’s also possible to configure GSLB to control access to the Search Head Clusters so that if an entire site fails, inbound search requests coming from remote locations will be directed to the remaining site.
Conclusion
If you remember nothing else, all you need to know is that the combination of...
- Splunk SmartStore
- NetApp StorageGRID
- Loadbalancer.org GSLB; and
- Loadbalancer.org local load balancing functionality
......provides a flexible, scalable, resilient and highly available Splunk architecture. Problem solved : )
For more information please contact sales@loadbalancer.org.