











It's the end of an era. After many years arguing that GSLB has no place on a proper load balancer, I've finally found a solid reason to add one to our product. Yes, you read that right! I've officially surrendered and given you a new GSLB to play with.
So for those that asked, on your heads be it!
Why Loadbalancer.org for GSLB?
The Engineers' choice for smarter load balancing
Genuinely, though, we've had quite a few requests for a GSLB over the last 15 years. After discussing the actual requirements, it transpired that 98% of these requests would be much better served by using one of the many 'GSLB as a service' providers such as Amazon route 53, DYN etc.
When you simply want public multi-site load balacing with health checking and geographic routing,then you have a multitude of great GSLB service providers to choose from.
Why did we finally add GSLB to our load balancer?
I've come across 2 common scenarios where an on-site GSLB is helpful:
- Fail-over between multi-site load balancers (when you don't have a stretched vlan)
- Least cost routing across the WAN when you have a multi-site active/active configuration.
Let's talk about a hypothetical scenario that I've discussed with many different customers in the past: linked sites with users located in both. Assuming the link is routed and it's not some fancy stretched VLAN/Subnet, inevitably you'll have different subnets on each site. This rules out your ability to have a simple floating VIP that fails-over.
Usually in that scenario, I would advocate a pair of appliances in each location. Each load balancer cluster would then configure the other site's virtual service (VIP) as its fallback server. Clients use their local VIP with its local servers, but in the event of all servers failing health checks, it will insert the fallback server. This of course is our VIP from the other site, allowing a successful failover accross a routed network.
While this offers fast and reliable failover in the event of all real servers failing health checks at either site, it doesn't help should the virtual service itself become totally unreachable. You would also probably need to use a per site Subdomain/FQDN or the local IP address itself to access the application specifically on either site, rather than a single Subdomain/FQDN. Unless you configure your local DNS servers in each site to respond only with the local VIP address instead.
How can you use the fallback server should both load balancers, the entire server room or anything else core to reaching the local VIP fail? You can't!
The fallback server is only good as a last resort if all real servers fail. Commonly people will resolve this problem by doing a manual DNS switch to serve the other site's VIP in the event of all real servers failing. This is fine but tedious and reactionary, so definitely far from the ideal solution.
Stop! You see I'm mentioning DNS in the solution already!
As people will usually be using an application's FQDN to access it, you could resolve this problem if you could only configure the DNS server with multiple A records. We can do that already.
But I don't want clients using the other site unnecessarily in a round-robin fashion. And we can do something about this too with most DNS packages.
Finally, you'll also want health checks to avoid serving up the results that have actually already failed. That's a little harder, but maybe we can script something...
Sticking plaster solutions
I've had these conversations and followed them down the rabbit hole many times before. Eventually we either settle for a simple solution with some manual intervention or try a complex homebrew solution at the DNS level. On occasion we've even considered using BGP!
Obviously these 'sticking plaster' type solutions have flaws. So in the past we have often recommended the installation of a GSLB from other vendors such as F5 Networks.
Over the last couple of years, though, we've been using the open source Polaris GSLB on a large customer site - and we've been seriously impressed because:
- It's easy to use
- It's fast
- It's secure
- And most importantly - it's easy to maintain with zero downtime.
What are the specific features you've implemented in your new GSLB?
- Reliable health-checking service supporting both TCP and HTTP(S) checks so that only healthy servers are returned on lookups.
- Failover, round robin and also a topology method that directs clients to servers in the same location.
- Capacity to return single or multiple answers at once - we can return up to 1024 records in a response!
- Option to fallback to any healthy server or refuse query.
It's not quite as fully featured as Amazon's Route53 or some of the other fancy cloud-based GSLB services out there. But for our needs it's ideal. In conjunction with the usual failover and high availability offered by our appliance, we hope this can add to our customer's toolset when deploying highly available applications.
Can you also use it for other scenarios? Sure, use it how you wish, and please do tell us what you do with it - we'd love to know!
So let's look at a diagram of the above scenario, two pairs of load balancers in highly available clusters which are also acting as 4 GSLB's.
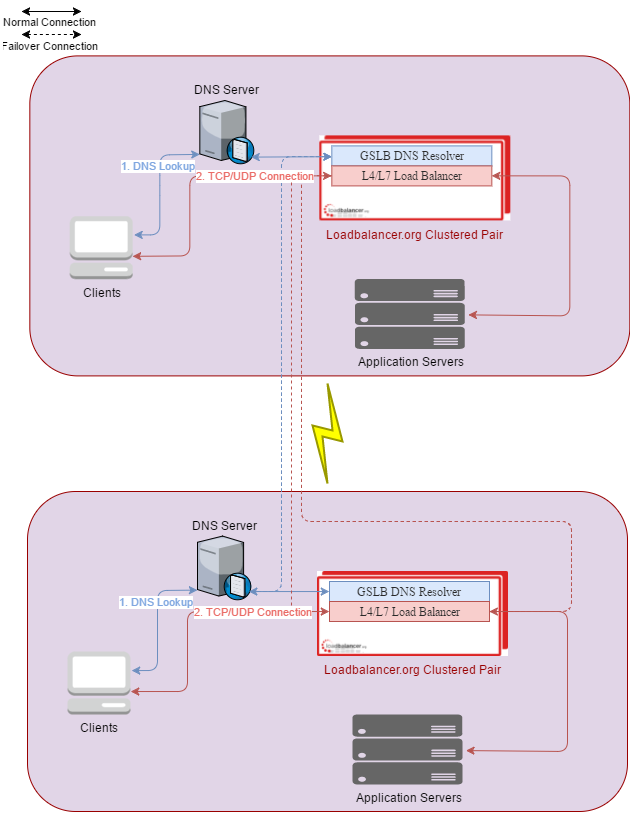
How does this all come together?
We have the load balancers providing traditional load balancing methods and health checks against the application servers on each site. A fallback server configured on each pair of load balancers references the other site, so that if all real servers fail health checks, your connections will continue via the local load balancers. And finally the GSLB is offering high availability accross both pairs of load balancers, so if the local load balancing cluster dissapears entirely, DNS should take us over to the other site automatically (albeit not as fast as an IP failover).
There are many other ways to implement such a solution, depending on your network topology and how the sites are connected. For example you could instead use the public address of the other site via the internet and just NAT to the load balanced VIP as you would for external users.
Excellent. So where is it, when can we get it and how much does it cost?
With the release of 8.3.1 GSLB will be added to your WUI for free. We've never charged for extra functionality and we're glad to say that this feature will also be included as standard feature on our appliance.

You'll find that we have a simple config example already defined which you can edit. But to make things easier I'll go over all of the possible options, and more importantly, how and when we might use them.
globalnames:
www.loadbalance.com:
pool: www-loadbalance
ttl: 1
pools:
www-loadbalance:
monitor: tcp
monitor_params:
port: 80
timeout: 1
lb_method: wrr
fallback: any
members:
- ip: 1.1.2.11
name: www1
weight: 1
- ip: 2.2.1.11
name: www2
weight: 1
Above is the simplest possible config. Two servers or answers have been configured with TCP health checks. We are not using the topology file, it's just "weighted round robin" or "wrr" so users may receive either result if healthy.
Let's set the "lb_method" to "twrr" so we can utilize the topology feature too:
globalnames:
www.loadbalance.com:
pool: www-loadbalance
ttl: 1
pools:
www-loadbalance:
monitor: tcp
monitor_params:
port: 80
timeout: 1
lb_method: twrr
fallback: any
members:
- ip: 1.1.2.11
name: www1
weight: 1
- ip: 2.2.1.11
name: www2
weight: 1
We just changed the lb_method to "twrr". However, we won't be able to apply these settings yet by reloading the service without an error, because we need to define the topology locations in the topology file first. Example:
# For overlapping networks the most specific match(longest prefix length) is returned.
location1:
- 1.1.2.0/24
- 3.3.3.0/24
location2:
- 4.4.1.0/16
- 2.2.1.11/32
To explain the above: your servers must have a subnet listed under a location. You can group subnets or IPs under each location so that clients from the associated subnets will use servers only from their local location. When using topologies all servers must be defined under a location by either using their entire IP/Subnet such as 1.1.2.0/24 or just a single IP address with a /32 subnet like 2.2.1.11/32.
With or without using topologies we can now restart the service, which will make the new configuration active.
Note: Typically we'll be reloading the service for config changes as this is not service interrupting to the GSLB.
Let's check if it works.
From Windows we can test our GSLB responds for our subdomain using nslookup:
C:\Users\me>nslookup -norecurse www.loadbalance.com 1.1.2.10
Server: UnKnown
Address: 1.1.2.10
Name: www.loadbalance.com
Address: 1.1.2.11
On Linux I'm doing the same using dig:
me@me:~> dig www.loadbalance.com @1.1.2.10 +noall +answer +norec
; <<>> DiG 9.9.9-P1 <<>> www.loadbalance.com @1.1.2.10 +noall +answer +norec
;; global options: +cmd
www.loadbalance.com. 1 IN A 1.1.2.11
Okay, that's great! It's serving up the correct results, so we know it's working.
Next, let's look at the Polaris Config and Topology Config in further detail.
Polaris Config
globalnames:
www.loadbalance.com:
pool: www-loadbalance
ttl: 1
pools:
www-loadbalance:
monitor: http
monitor_params:
use_ssl: true
hostname: www.loadbalance.com
url_path: /healthcheck.php
lb_method: twrr
fallback: any
max_addrs_returned: 2
members:
- ip: 1.1.2.11
monitor_ip: 1.1.2.15
name: www1-dc1
weight: 1
- ip: 1.1.2.12
name: www2-dc1
monitor_ip: 1.1.2.15
weight: 1
- ip: 2.2.1.11
name: www1-dc2
weight: 1
- ip: 2.2.1.12
name: www2-dc2
weight: 1
globalnames:
Here we can define our subdomains; we'll be delegating to the GSLB. You can have more than one so just define them nested under this section like so:
globalnames:
www.loadbalance.com:
pool: www-loadbalance
ttl: 1
www2.loadbalance.com:
pool: www2-loadbalance
ttl: 1
pool:
Specifies the pool of servers to use.
ttl:
The time to live, how long to trust the answer before looking it up again, don't set too high or the health checks will be less useful.
pools:
This section is where you define the backends. You configure a pool of member servers or answers and set up the health checks and other options. Much like the "globalnames:" section, we can nest multiple pools here:
pools:
www-loadbalance:
monitor: tcp
monitor_params:
port: 80
timeout: 1
lb_method: wrr
fallback: any
members:
- ip: 1.1.2.11
name: www1
weight: 1
- ip: 2.2.1.11
name: www2
weight: 1
www2-loadbalance:
monitor: tcp
monitor_params:
port: 80
timeout: 1
lb_method: wrr
fallback: any
members:
- ip: 1.1.2.11
name: www1
weight: 1
- ip: 2.2.1.11
name: www2
weight: 1
Monitor: http/tcp/forced
The monitor subsection is where you define the health check; you have a choice of http, tcp or forced. Once you have selected your probe type you can then define its settings.
HTTP Parameters
monitor_params:
- interval: How often to perform a health check, min 1 max 3600 seconds.
- timeout: timeout for check in seconds, min 0.1 max 10.
- retries: Number of retries before declaring member DOWN, min 0 max 5.
- use_ssl: Whether to use SSL for the check, defaults to "false" if not specified, to enable set to "true".
- url_path: URL path to request, defaults to "/" if not set.
- hostname: Host header to use during the test, when using SSL this will also supplied in SNI.
- port: port number to check, if no value is provided it will default to "80" unless "use_ssl" is set to "true" then it defaults to 443.
- expected_codes: An array of expected codes that will pass such as 200,201,202, defaults to "200".
TCP Parameters
monitor_params:
- interval: How often to perform a health check, min 1 max 3600 seconds.
- timeout: Timeout for check in seconds, min 0.1 max 10.
- retries: Number of retries before declaring server DOWN, min 0 max 5.
- send_string: String to Send after connecting.
- match_re: A regex to match in the response(Case insensitive).
Forced parameters
- status: Either "up" or "down" but if not provided it defaults to "up"
Members:
The members subsection is where you define the servers or answers our GSLB will be providing. Once you have defined its IP address you need to at least provide a name and weight.
- name: Server name / label
- weight: Weight of server between 0-10
- monitor_ip: Optional IP address to issue health checks against, allows you to configure health checks on a server that is different to the server listed
Lb_methods: wrr/twrr/fogroup
This is where we define the scheduler or method of load balancing.
- "wrr" Weighted round robin, round-robin with weighting.
- "twrr" Topology weighted round robin, as above but the topology file is considered to provide preferential answers to clients in the same "location" as servers.
- "fogroup" Failover Group, first healthy IP is handed out continuously unless the server becomes unhealthy, then, the next healthy server is used.
Fallback: any/refuse
Define what to do when all servers fail health checks. Options include use any server or refuse the connection entirely.
- "any" default, any configured server may be used as the fallback server.
- "refuse" refuse query when all servers are down.
max_addrs_returned: <num>
Number between 1-1024, if not specified then this defaults 1.
Topology Config
Next, we have the topology configuration, this can be ignored if you are using either "wrr" or "fogroup" lb_method's, it's only used for "twrr". However, when enabled all servers defined in the Polaris Config must match a configured locations subnet.
# For overlapping networks the most specific match(longest prefix length) is returned.
location1:
- 1.1.2.0/24
- 3.3.3.0/24
- 10.0.0.0/8
location2:
- 4.4.1.0/16
- 2.2.1.11/32
- 172.16.254.0/16
- 192.168.0.0/24
<location name>:
This is where we define our locations, each location can contain multiple subnets to group clients to answers.
Checking Statuses
You can get information out of the GSLB by issuing one of two commands via the CLI or by using Local Configuration > Execute A Shell Command in the WUI:
Check Health State:
/opt/polaris/bin/polaris-memcache-control 127.0.0.1 get-generic-state
{
"timestamp": 1510789237.8592148,
"globalnames": {
"www.loadbalance.com": {
"pool_name": "www-loadbalance",
"ttl": 1,
"name": "www.loadbalance.com"
}
},
"pools": {
"www-loadbalance": {
"members": [
{
"weight": 1,
"retries_left": 2,
"ip": "1.1.2.11",
"region": "location1",
"status": true,
"status_reason": "monitor passed",
"monitor_ip": "1.1.2.11",
"last_probe_issued_time": 1510789236.7592874,
"name": "www-dc1"
},
{
"weight": 1,
"retries_left": 0,
"ip": "2.2.1.11",
"region": "location2",
"status": false,
"status_reason": "OSError [Errno 113] No route to host during socket.connect()",
"monitor_ip": "2.2.1.11",
"last_probe_issued_time": 1510789236.759294,
"name": "www-dc2"
}
],
"last_status": true,
"max_addrs_returned": 1,
"lb_method": "twrr",
"monitor": {
"retries": 2,
"hostname": "www.loadbalance.com",
"expected_codes": [
200
],
"interval": 10,
"url_path": "/",
"port": 80,
"timeout": 5,
"use_ssl": false,
"name": "http"
},
"fallback": "any",
"name": "www-loadbalance"
}
}
}
We can see from above that our first server has passed the health check while our second is currently failing, we get other info too such as the time of the last probe and number of remaining retries. This is all displayed inside of the printout of the full running configuration which is handy to remind you if you do forget to reload.
Check query distribution State:
/opt/polaris/bin/polaris-memcache-control 127.0.0.1 get-ppdns-state
{
"timestamp": 1510789237.9490006,
"pools": {
"www-loadbalance": {
"lb_method": "twrr",
"fallback": "any",
"dist_tables": {
"_default": {
"index": 0,
"rotation": [
"1.1.2.11"
],
"num_unique_addrs": 1
},
"location1": {
"index": 0,
"rotation": [
"1.1.2.11"
],
"num_unique_addrs": 1
}
},
"max_addrs_returned": 1,
"status": true
}
},
"globalnames": {
"www.loadbalance.com": {
"ttl": 1,
"pool_name": "www-loadbalance"
}
}
}
Here we can check what answers will be served to a client, we have a default section listed which is used when a topology is not configured or when none matched the client's source address. This has a "rotation" defined which shows the answers available. We also have "location1" below that which will be used if clients are sourced from it's listed subnets in our topology config. Currently, as we have no servers up in "location2" it is not actually listed so clients from it's defined subnets will be using the default answer section instead.
Enabling the service and restarting / reloading
Unfortunately, at the time of writing this blog, the reload button hasn't been added yet so doesn't show on configuration changes, because of this you'll need to restart and reload the GSLB from the "Maintenance > Restart Services" menu in the WUI on each appliance. Reloading isn't service interrupting even if you make a configuration error the last loaded good configuration will still be active. Restarting, on the other hand, is service interrupting because ALL services that form the GSLB will be restarted. Initially, however, you should restart it as it will also enable it at boot time as well as load your first GSLB configuration.
Okay, did we leave something out? We've configured it and enabled it by restarting the service from "Maintenance > Restart Services". But, How do we actually turn this stupid thing off if it doesn't work out!? Well, we haven't given you a nice way to turn the GSLB off quite yet...
Disabling the GSLB
So to turn it off and disable it at boot time you'll need to issue the following two commands via the CLI or using the "Local Configuration > Execute a Shell Command" option in the WUI:
service gslb stop
chkconfig glsb off
Delagating your subdomain to your GSLB's using Microsoft's DNS Server
Only one thing left to mention, to make use of the GSLB in your network we'll need to configure the local DNS servers to delegate the subdomain(s) to our GSLB's. I'll show you how to do that for a Microsoft DNS server but it's fairly easy to do in other DNS servers too.
Microsoft's DNS Server
Delegating a subdomain is a fairly easy process, simple:
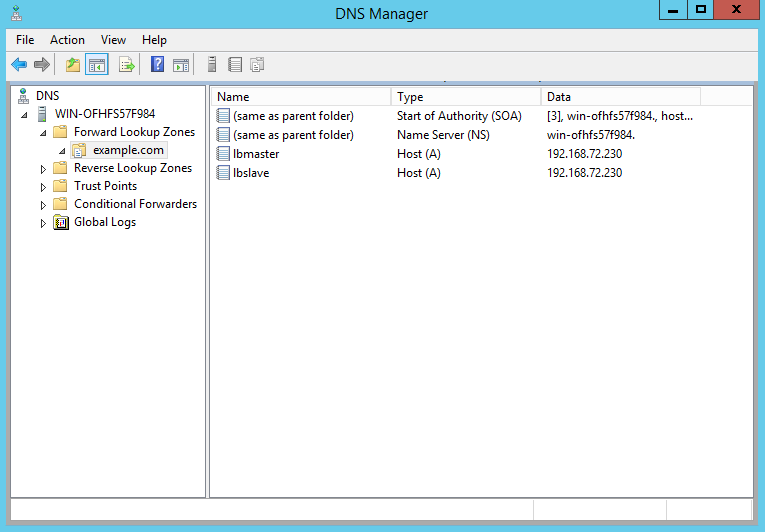
- Open DNS Manager and create A records for each GSLB enabled load balancer in your domain(lbmaster.example.com,lbslave.example.com...).
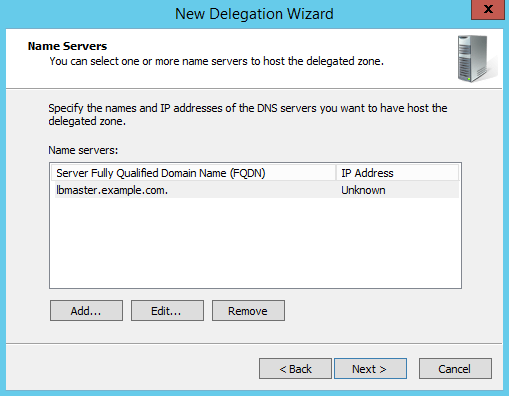
- Once complete and only once you've configured the GSLB's and tested that they actually work delegate the subdomain(s) to the GSLB's. Create a New Delegation and using the wizard provide your subdomain and add your GSLB's by their new FQDN's from step 1.
- Test the Delegation - From Windows we can test our DNS server responds for our subdomain using nslookup and it should reurn the GSLB's.
C:\Users\me>nslookup -norecurse www.loadbalance.com 1.1.2.2
Server: UnKnown
Address: 1.1.2.2
Name: www.loadbalance.com
Served by:
- lbmaster.loadbalance.com
1.1.2.10
www.loadbalance.com
Now we'll do that again but remove the "-norecurse" option to test we get the correct result back from one of the GSLB's(For dig remove the "+norec").
C:\Users\me>nslookup www.loadbalance.com 1.1.2.2
Server: UnKnown
Address: 1.1.2.2
Non-authoritative answer:
Name: www.loadbalance.com
Address: 1.1.2.11
Great!
Need assistance or have any questions?
So to wrap this up you should be equipped now to configure the GSLB, any problems, you can always reach out to our support team or just comment below.