

The media industry had lots of fun at the expense of e-commerce outlets on Black Friday mercilessly reporting on site crashes and outages.
My wife yelled that I needed to 'fix the Internet' when Argos.co.uk would not respond immediately to her demands on Friday evening. However on closer inspection i.e. reading the page Argos was handling the situation in a very fair and simple way.
The holding page displayed apologised because the site was very busy, and within about 2 minutes it let her into the web site to start shopping (nice little Javascript re-direct built into the sorry we are busy page).
If you need to implement this kind of functionality for your e-commerce site then it is pretty simple to do with the Loadbalancer.org appliance:
What we basically need to do is track the number of valid users shopping on the web site with an application cookie, and set a limit on the total number we think our application can safely handle.
For this configuration we are setting the limit at 5000 users over a 10 minute period (you don't want to time people out when they spend 5 minutes just looking for their credit card!).
On the Loadbalancer.org appliance v7.6.3 you would configure this VIP as a Layer 7 Manual Configuration; this new functionality ensures that you have complete control of the configuration file and yet the system overview still shows the servers and allows you to you to control them.
Back to the actual configuration (heavily borrowed from HAProxy Over Usage Protection)
listen L7-Test
bind 192.168.64.27:80 transparent
mode http
acl maxcapacity table_cnt ge 5000
acl knownuser hdr_sub(cookie) PHPSESSID
http-request deny if maxcapacity !knownuser
# define a stick-table with at most 5K entries
# cookie value would be cleared from the table if not used for 10 m
stick-table type string len 32 size 5K expire 10m nopurge peers loadbalancer_replication
# Use the applications own php session id to track users - you could track users who are in the shopping basket with a different cookie....
stick store-response set-cookie(PHPSESSID)
stick store-request cookie(PHPSESSID)
# Lets use the built in Loadbalancer.org fallback page - you can edit this with a nice holding message and javascript re-direct after timeout.
errorfile 403 /usr/share/nginx/html/index.html
balance leastconn
# We can use our own internal cookies for session tracking per server as well.
cookie SERVERID insert nocache
server backup 127.0.0.1:9081 backup non-stick
option http-keep-alive
option forwardfor
option redispatch
option abortonclose
maxconn 40000
server Test1 192.168.64.12:80 weight 100 cookie Test1
server Test2 192.168.64.13:80 weight 100 cookie Test2
I think this is a very powerful and useful feature for any e-commerce site trying to deal with Black Friday type events.
Interestingly enough most of the people I talk to disagree with me and say that these sites should have invested more money in capacity to avoid the massive loss of face and bad publicity...
But just how much would that cost?
And is it even achievable if your database is overloaded? (without a complete architecture re-design) we are not all Amazon after all.
I used to manage the IT infrastructure for Crocus.co.uk way back in 2003 and recall implementing this kind of fix at the application layer for the Valentines day rush.
We were very close to losing the site from the sheer volume of people trying to do last minute valentine flower orders. If we had not done the fix then the site would have collapsed and 25,000 pre-ordered bunches of roses would have gone to waste.
But what about other methods of handling traffic over load on your site?
One of the popular methods of handling traffic over-load is to use a cloud service provider such as Akamai or Queue-it, these services are great, simple to set up and do exactly what most customers require. However I always worry about latency and scalability when using an outsourced cloud provider. Its very hard to get accurate figures or specifications from these providers, and from anecdotal evidence i.e. most of the people I asked about what happened on Black Friday most of these service providers also struggled to handle the load and had major problems with consistency and reliability.
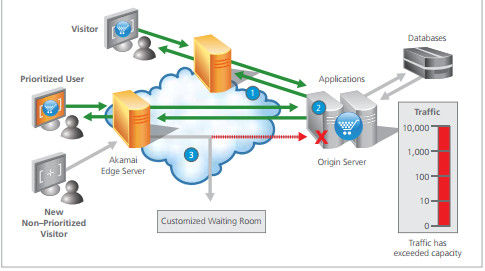
My totally un-scientific findings (word of mouth and gut-instinct) tell me that Akamai performed well and other providers struggled, I'd be interested to hear if anyone has some solid numbers on this kind of thing?
At Loadbalancer.org we are starting to focus on Security, High-Availability and real performance of application traffic management, by real performance we mean the actual performance you can expect in realistic scenarios (i.e. not just saying wire-speed) so that you can plan your deployments with confidence.